
“Everything fails, all the time.” These famous words from Amazon’s CTO, Werner Vogels, still hold true! Time and again, we’ve seen that a single point of failure can bring the digital world to its knees (in what IT service management (ITSM) terms a “major incident”). Think about last year’s CrowdStrike debacle or the recent AWS outage. These involved two very different players, but for each, one small failure quickly cascaded into widespread disruption. While end-users were bearing the full brunt of downtime, IT teams were racing against the clock to restore services.
Now, if there’s one thing major outages like these have made clear, it’s that sometimes they’re simply inevitable, and they catch you off guard.
That’s exactly why, instead of relying solely on traditional incident management workflows, IT teams need to diversify and modernize their approach by infusing intelligence into their incident response flows. This can help incident response teams (IRTs) spot subtle anomalies that could otherwise slip through human analysts. And as we now step into the agentic era, it’s clear that artificial intelligence (AI) will only play an even greater role in reshaping how IT incidents and major incidents are detected, analyzed, and resolved.
The Role of AI in the Evolution of Major Incident Management
Incident response has involved AI for a while.
Early AI in ITSM: Machine Learning and Assistive Intelligence
Over the years, incident management practices have benefited from machine learning through the application of smart categories, subcategory predictions, and intelligent technician assignments.
How Generative AI Accelerated Incident Resolution
The advent of generative AI (GenAI) and its subsequent adoption in ITSM platforms have further enabled technicians to accelerate resolution times and have helped end users self-resolve their issues by making relevant knowledge much more accessible.
Why Major Incidents Demand More Than Traditional Automation
Given the high stakes of major incidents, both the process and its stakeholders stand to gain from additional AI capabilities, such as AI-powered impact and root-cause analysis, and streamlined contextual communication. Today, with the rise of AI agents and Agentic AI capabilities, we can now craft more powerful major incident management workflows that minimize the business impact of major incidents and proactively help avoid them.
Let’s look at a quick use case to understand how the application of AI for major incident management has evolved over the years.

A Real-World Major Incident Use Case in Retail IT
The Challenge – A Database Upgrade Triggers POS Failures
A global retail chain decides to perform an organization-wide digital transformation project to enhance its operations. As part of this effort, the IT team begins upgrading its database infrastructure to a newer version of Microsoft SQL Server.
Soon after the rollout, the point-of-sale (POS) systems across multiple stores start going offline. Store employees are unable to process transactions, customers are queuing up, and operations come to a standstill.
The Root Cause – Missed Compatibility Testing
The cause is later traced back to an incompatibility between the upgraded SQL server and the existing POS systems. This issue went unnoticed because compatibility tests weren’t conducted beforehand.
Comparing Major Incident Response Approaches
Remediation can be viewed through:
- Traditional best practice workflow
- Best practice workflow with simple AI features
- Agentic AI augmented workflow
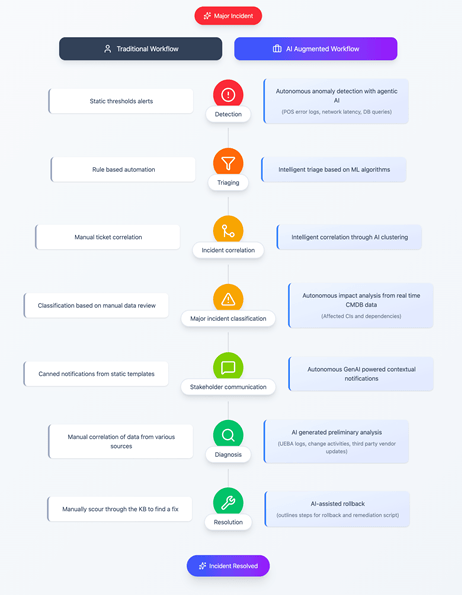
1. Traditional Major Incident Management Workflows
- Retail store employees across multiple stores start flooding the IT service desk with incident tickets.
- Rule-based automations are triggered to triage the tickets that meet the set conditions.
- Technicians manually review the tickets to identify similarities and determine whether they are a part of a larger issue.
- Once patterns are recognized, the technicians manually link the related incidents to a major incident record.
- The IRT reviews all technician notes and ticket conversations to understand the issue.
- The IRT sorts through an overload of data from other disjointed sources, such as User and Entity Behavior Analytics (UEBA) logs, recent change records, privileged access logs, database activity, and third-party update histories.
- This eats up a lot of IRT time as members are debating the probable root cause.
- Stakeholder communication is automated, but it follows standard, canned notification templates that provide limited details.
- The IRT, after a long root cause analysis, determines that a recent database upgrade is causing the POS software to fail and reverts to the previous version to fix the issue.
- The workflow adheres to best practices, but it is reactive, labor-intensive, and slow to restore service.
2. AI-Assisted Incident Response with Intelligent Automation
- As POS failures begin, monitoring tools generate alerts and log them as tickets in the ITSM platform.
- AI-powered triage automatically categorizes, prioritizes, and routes incoming tickets. This reduces the need for each incident ticket to meet rigid rule sets for the triaging automation to kick in.
- AI case clustering consolidates related tickets into a single major incident record, eliminating duplicate effort and manual correlation of similar tickets.
- Meanwhile, a GenAI-powered virtual support agent helps generate tailored updates for different stakeholder groups, including organizational announcements, end-user responses, and technician notes. Instead of relying on static templates, these communications are generated on demand.
- The virtual agent generates instant ticket summaries to bring IRT members up to speed by providing an overview of the ticket conversations, ticket parameters, and technician notes.
- The IRT then performs a root cause analysis, confirms that the database compatibility issue is the root cause, and deploys a fix.
- After remediation, the virtual agent assists with generating the post-incident review report, reducing the documentation effort required from the team.
3. Agentic AI-Augmented Major Incident Response
- An AI agent with access to the observability dashboards detects a surge in logs showing failed POS API calls to the SQL server.
- It checks the network traffic, authentication attempts, and system logs. It observes that these failures are occurring across multiple retail locations, indicating a widespread issue.
- Meanwhile, IT service desk queues begin to flood with tickets from store employees.
- The AI agent, which also has access to the ticketing system, notifies the IRT with a summary of its findings and asks whether it should create a major incident ticket and initiate the response workflow.
- Upon approval, it clusters all similar tickets together and links them to a single major incident ticket.
- It then automatically responds to the end-users who raised those tickets, informing them that IT is aware of the issue and is actively working on a fix. (The responses are sent autonomously instead of being generated on demand.)
- Another AI agent, with access to the organization’s change management records, correlates the timing of the incident with a recent database upgrade. It finds that shortly after the SQL server was upgraded, the POS systems began failing to connect.
- The agent compiles these insights and shares them with the IRT, enabling the team to quickly identify the database upgrade as the root cause instead of spending valuable time troubleshooting from scratch.
- The AI agent, trained on domain-specific knowledge and with access to the IT service desk’s historical change documentation, recommends reverting to the previous SQL server version to resolve the incompatibility issue.
- To stop the current version and restore the backup of the older one, the AI agent also suggests a remediation script outlining steps.
- Once the IRT approves, the AI agent assists in executing the rollback, helping restore normal operations across all stores.
The Future of Major Incident Management in the Agentic Era
It’s safe to say that AI has seen massive advancements over the years. From deterministic chatbots to GenAI-powered virtual agents and now to autonomous AI agents, we have come a long way.
Thankfully, ITSM as a discipline has kept pace and evolved alongside these changes. As we step into what looks like the agentic era, the use cases for AI-driven ITSM, and major incident management in particular, will only continue to grow. The focus will shift from simply speeding up workflows to building systems that can think, decide, and act with minimal human input, thereby changing how organizations handle disruptions and deliver value.

Alexandria Nisha
Alexandria is a passionate explorer of the ITSM realm and is keen on learning and sharing insights about the ever-evolving ITSM landscape. With a fresh perspective on the world of ITSM, she loves writing best practice articles and blogs that help IT service delivery teams address their everyday service management challenges. In her free
time, you can catch her binge-watching all things Formula 1 and talking about, like her life depended on it, why Lewis Hamilton is one of the best racers ever.
