
I bet by now you’ve heard about the AWS S3 outage. Somewhat ironically, at 17:47 last night I was watching a training video on Amazon Web Services (AWS) Simple Storage System (S3) best practices when the video stopped. The video service, hosted on AWS as you would expect, wouldn’t refresh so I decided to look up some AWS S3 documents instead. However, my browser displayed a HTTP 500 (service unavailable) from aws.amazon.com. It was highly unusual and thus unexpected.
The AWS status page was showing a sea of green so, like anyone else looking for near-real time news, I searched Twitter for “AWS 500”. Was anyone else seeing this? Yes, but just a few people. I’d encountered what was the start of the “February 28th AWS US-East-1 S3 Increase Error Rates,” or the Twitter trend called “Amazon S3 Outage.”
Cue social media reactions on the AWS S3 outage: sarcastic meme-driven humor: “Oh my god the Internet is dead”; shrieking; gloating competitors; private cloud apologists; and anti-cloud ideologues.
However, there is “signal” in this social noise and here are five important things to take away from the AWS S3 “event” from an IT service management (ITSM) perspective.
1. The AWS S3 outage: AWS wasn’t down, but US East 1 was “impaired”
AWS is a global cloud service made up of 16 regions and counting. When people on Twitter shrieked “AWS is down!” this wasn’t true. The reality was that an important service in one region was impaired, but other regions were A-OK.
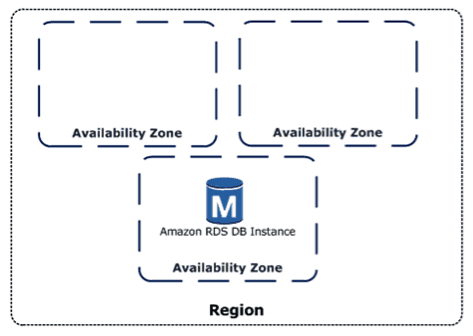
These regions are completely independent of each other, except for the special US-East-1 region which handles some global services. And inside each region you have multiple availability zones (AZ) which you can think of as datacenters. These datacenters are resilient with their own redundant power and connectivity, and they’re also connected to each other inside the region so that services like S3 can automatically replicate your data three times – giving you data durability of eleven nines. The standard availability of the S3 service is four nines.
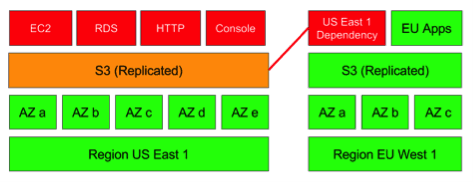
The AWS S3 outage we experienced yesterday was the S3 service in the Region US-East-1 suffering from what AWS called “high error rates” and the service was impaired. Other regions were mostly OK, such as EU-West-1, but the US-East-1 S3 event had a wider “blast radius” because:
- When you create an S3 bucket and don’t specify a region, the default is US-East-1.
- US-East-1 is a special region, sometimes called a “global region,” because it’s the default endpoint for “global resources” such as hosted zones, resource record sets, health checks, and cost allocation tags.
- The S3 in US-East-1 is used by a lot of AWS services including the AWS Status Page and the AWS documentation.
- US-East-1 is huge (five AZs) and is older and more popular than other regions, running a lot of well-known online applications that use S3 to host their data. Therefore, the blast radius was very public on Twitter, with many companies explaining that their downtime was due to AWS.
- US-East-1 is in “spy country,” which will please the conspiracy theorists!
Therefore, any impact to a core AWS service in a core AWS region like U- East-1 is likely to have a ripple-out service impact across a wide blast radius.
2. Why did the S3 impairment in one region have such a big impact?
S3 is sometimes referred to as “the storage for the Internet” because it’s used everywhere. Any object like a thumbnail or log record put into it is easily accessible over HTTP from anywhere. Your app doesn’t have to be running on AWS, it could be running in your datacenter and accessing S3 over the Internet. Hence the AWS S3 outage affected a lot of people (and companies).
When Amazon S3 is down. #awscloud #awss3 pic.twitter.com/KQo4sVvkAl
— Fernando (@fmc_sea) February 28, 2017
S3 is the epitome of one of the core “essential cloud characteristics” from the NIST Cloud Standards: broad network access. It’s what makes AWS the public cloud leader. It also means that, because S3 is cheap and easy to use by any user with no special skills required, it’s used universally as the backing store for many trillions of objects serving millions of requests per second. Both AWS services and customer applications use S3, so it was like a house of cards even though other regions’ S3 was working fine.
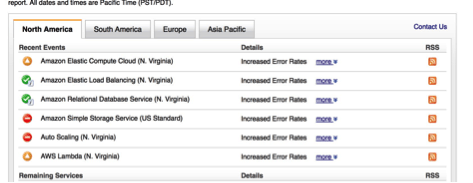
Awkwardly, even the status indicators on the AWS service status page rely on S3 for the storage of its health marker graphics. And thus, during the outage the status page was showing all services as green despite the service being “impaired.” AWS did add a banner to the status page to explain why this was happening, and they did issue this tweet to keep customers informed.
The dashboard not changing color is related to S3 issue. See the banner at the top of the dashboard for updates.
— Amazon Web Services (@awscloud) February 28, 2017
Twitter was awash with companies apologizing to customers for service degradation or outage, and looking at SimilarTech data – the number of sites they claim are running on AWS S3 is significant:

Interestingly home users were also affected by the AWS S3 outage, with reports that parents couldn’t get Alexa to sing nursery rhymes to their children, i.e. failing to access Amazon Music, and home automation systems locking people in their homes (or into darkness).
3. How can you protect your business from AWS S3 outage “events”?
These kind of AWS events are rare but you have to be prepared for them to happen. These aren’t unique to AWS, they happen to all other service providers and enterprises. Application availability is ultimately the customer’s responsibility even though AWS provides a lot of features to protect them from these kinds of events, i.e with multi-AZ and multi-region availability.
Specifically for this outage, there’s an AWS S3 feature called Cross-Region Replication that customers could implement in tandem with application and DNS changes to protect themselves from a single-region S3 failure. It works for individual S3 buckets when versioning is enabled. And, after replication is enabled on the versioned bucket, any uploads to a bucket (“the source bucket”) in one region are asynchronously replicated to a bucket in another region (“the destination bucket”). This solution is documented in the S3 Developer Guide, Cross Region Replication.
4. People don’t always use the redundant AWS services
Even though there are multiple AZs in one region, and multiple regions across the world, not everyone uses these availability features for a range of reasons:
- Unknown dependencies on S3. An application running in one region can be accessing data from an S3 in another region across the Internet – it’s just a URL, and developers are known to hardcode filesystem paths and URLs into their code. As applications age, do developers keep track of where data is coming from? You would think so, but humans make mistakes and dependencies can accrue over time to create fragile applications.
- Cloud-immigrant applications. Within AWS, customers can deploy applications that are not cloud native and cannot benefit from “distributed computing” that multi-AZ and multi-regions offer. It might be an old, monolithic, and fragile COTS (commercial off-the-shelf) product that stubbornly sits in a “snowflake” virtual machine running the database locally. If this virtual machine is in a failing AZ or region, then it’s back to standard backup, restore, and disaster recovery scenarios. EC2 in the US-East-1 region was affected because many EC2 virtual machines use S3 for storage.
- Availability isn’t worth the cost. There are those that understand the technology but don’t want to pay for the extra resources such as multi-AZ databases, or pay for lots of snapshots, or pay for cross-region replication or many of the other HA/DR (high availability/disaster recovery) features AWS makes readily available. “That app isn’t worth the costs of availability” might be the view – but has this been really worked out? Which other applications rely on this application?
This isn’t unique to cloud. For as long as IT has been around, people have chosen to save money on HA/DR, or not even known it was something they needed to consider for when there’s a AWS S3 outage.
5. “Knee Jerks” attempt to muddy the water
Whenever AWS has an issue, such as this AWS S3 outage, there are a three types of commentator to surface on social media, what I like to call “Knee Jerks”:
- The AWS-bashing competitor: “AWS has an outage! Time to reconsider and use our cloud.” It’s unlikely that you will see Azure or Google bashing AWS but you might see an anti-cloud enterprise technology vendor or smaller, regional service provider naively bashing AWS during an outage. I don’t know any businesses that are impressed by competitor bashing.
- The hybrid/private cloud ideologues: “Public cloud places all your eggs in one basket and is flawed – use our hybrid cloud and hedge your bets.” Whatever people say hybrid cloud might be, and there’s no consensus or standard, it couldn’t do what S3 does. So this point is moot and shows a lack of understanding of modern Internet and cloud architectures.
- The anti-cloud on-premises techie: “If it was your own kit you’d be able to troubleshoot it yourself! Can’t do that in the cloud!” But this is the whole point of cloud – I don’t want to troubleshoot it myself! AWS has all the skills and know-how and resources I don’t have. This is usually a techie blinded by their fear of the cloud, who wants us to build IT systems in a shed at the end of their garden.
It’s unlikely that anyone who understands AWS will pay any attention to this kind of rhetoric, but non-cloud-savvy business users might unfortunately be influenced by the kind of fear, uncertainty, and doubt spread based on the AWS S3 outage.
The calm after the AWS S3 outage storm
Eventually, AWS got it status page working and the AWS S3 outage didn’t look pretty, in fact it was commented on that some long-running cloud users had never seen this before. It’s quite a testament to AWS long-term reliability:
AWS will fix this issue and their service will return to normal (and will be by the time this is published). Then it will work out how to never have this particular issue/problem again – they have people like James Hamilton who live to find and solve these issues. And if you use AWS, then James is working for you.
AWS will also produce a post-mortem and they are unique in leading cloud service providers in doing this – in my experience, many cloud service providers either don’t write outages up, or merely provide an exec-level generic blog piece.
In the AWS S3 outage post-mortem, we’ll find out what went wrong, how they fixed it, and what AWS is going to do better. And I’m certain that they will also tell their customers how they can do things differently too.

Steve Chambers
Steve Chambers generates real-time analysis on the topics of Cloud, DevOps, and ITSM. Steve helps organizations that range from global to local, commercial to public sector, and startup to enterprise. With these organizations, Steve operates at the conjunction of cloud service providers and organizations that consume their services, and analyzes and advises on the impact on their people, process, and technology.
Steve's career spans more than twenty years including banking, consulting engineer with Loudcloud, professional services and presales management at VMware, Cisco and VCE and executive CTO office at Atos Cloud,and numerous roles with startups in the cloud software business.
In addition to his day job, Steve is also an Associate Consultant at ITSM.tools.

3 Responses
Good stuff. What happened to reason #3?
Good spot John. We lost #3 in copying the text in segments into WordPress. It will reappear soon. Thanks.
Apologies, the missing number 3 was my fault as I juggled with adding all the images in. Thanks for spotting, it’s now there.