
What happens when machine learning – computer algorithms that automatically learn and improve from data and experience – leads to the crash of your IT systems, shuts down servers and applications, or takes actions you cannot have control over? Machine learning is the foundation of AIOps (AI for IT Operations) and automation, but to what extent can we depend on it, and how reliable is it? Should we let it be autonomous and adaptive, or seal it and update it manually? To formulate this question more accurately, how dynamic and adaptive should our machine learning algorithms be?
Machine learning in the context of IT service management (ITSM)
We may have raised some less positive points about machine learning at the beginning, however, these are the points we cannot avoid or turn a blind eye to it. The promise of machine learning is great and the many benefits it brings to us are significant. In the context of ITSM and IT operations, for example, the promise is to increase performance, reduce costs, and relieve IT operators from mundane, time-demanding tasks. However, with great promises comes great responsibilities, and in this article, we discuss the risks of using machine learning in your business and how to deal with it.
The risks of using machine learning
Using machine learning within your business may involve various risks that you have to manage and look out for. Factors that could influence the reliability of your machine learning model and form a risk could be: the accuracy, biasedness, environment, or hidden complex behavior.
The risks could be inherent or external. Inherent risks would be uncertainty in the parameters of your model that could affect your predictions. External risks would be when the environment in which the system is making decisions is changing, like due to certain trends (the increase in CPU due to lockdown, for example) your business applications might behave differently than the machine learning model was initially trained for. To get a better insight into these risks, let’s take a deep dive into the dynamics of these risks.
Accuracy vs. reliability – what’s the difference?
Consider machine learning as the automated model-building process based on learning patterns from large datasets and making predictions based on the learned patterns. The goal of the learning is to create intelligence on the behavior of the data and anticipate new behavior by predicting it. When the performance of a trained machine learning model looks promising, like having a high accuracy score and ready to be used, can we safely deploy it? It’s one thing to have high accuracy scores and good performing models; however, it’s another thing to have a reliable output that can be trusted.
Accuracy and reliability in supervised machine learning
For example, if a supervised machine learning model needs to classify whether the data is trendy or not {trendy, notrendy} for anomaly detection. It receives a new stream of unseen time series data from a new application, different from the one it trained on first; the decision score is 100% accurate, but can we trust the output in this case? The answer would be “no,” because the model operates outside of its domain (as the environment in which the data was initially processed and the model is now operating in have changed).
How reliable should your machine learning model be?
It’s important to know what a reliable, appropriate accuracy would look like for your machine learning model in the context of your business. And how to deal with the uncertainty in your machine learning model. The following question could frame the right approach to deal with this issue. Would a 100% accurate decision score be reliable all the time and generalized to new data, or be overfitted (only trained) to a particular behavior and would break down when the incoming data changes with the behavior? There is a constant tradeoff between accuracy and reliability. Big data might reduce this model uncertainty. Having large amounts of data would improve the accuracy and the reliability of your machine learning.

However, if you don’t have large amounts of data for a particular case within your business, a different approach of modeling with machine learning could be pursued. There is an increased interest in machine learning and artificial intelligence with limited datasets. A data-centric approach is an example to create models with limited datasets by focusing on the data (improving the data quality) rather than using model-centric approaches (improving algorithms, model architectures).
It’s the environment – stupid!
A particular challenge to the reliability of your machine learning is assuming that both training and subsequent datasets share the same underlying distribution and domain it learned from. When you don’t account for the uncertainties and risks that the change of environment brings to your machine learning model, it wouldn’t take long to lose reliability in your models. For example, if you train a model to predict trends in CPU data of your applications, the model only expects input data related to these applications. Machine learning is only as good as the data it can learn from. So what does the model predict when the underlying casualties between inputs and target do change or the prediction target itself is altered?
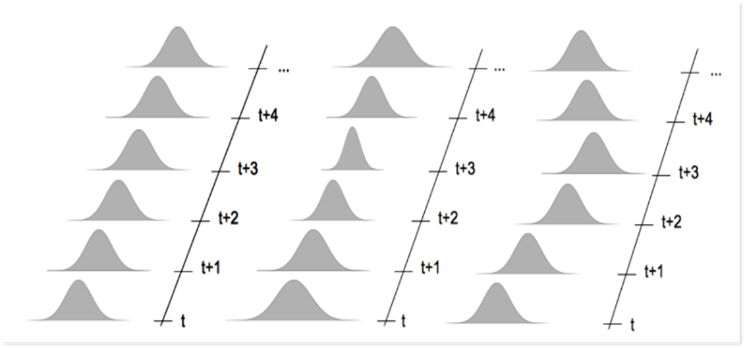
Data (CPU, memory, etc.) can change over time and deviate from the expected behavior within certain limits – ideally, we expect data to behave like the distributions on the most left part of the plots, but the data behaves mainly like the distributions on the most right part of the plots.
In a real-time business environment, a shift or change in the behavior or environment of the applications could be caused by hidden dependencies. Or simply by human activity. Causes that cannot just be captured in a model or predicted beforehand. When change is the only constant in these cases, machine learning models should be dynamic and be able to adapt to changing behavior of the data and the surrounding environment. You can try to gather more data and try to capture the complex hidden dependencies for example, but how much data is enough and can we, by gathering larger and larger datasets really, capture the unknown unknowns? “To some extent” could be an answer, since making predictions involves mysteries and uncertainties we cannot solve and deal with by modeling only.
The mystery of predictions
A major challenge that could influence the reliability of your machine learning is when you make predictions (predicting future values). Predictions are surrounded by uncertainties and mysteries. A good discussion on uncovering the mysteries of predictions is written in ‘Mystery of Prediction in Anomaly Detection.’ We can deal with uncertainties; however, a mystery cannot be answered; it can only be framed by identifying the underlying critical factors (known and unknown) and applying some sense of how they’ve interacted in the past and might interact in the future. Especially in the case of out-of-sample predictions or predictions based on unseen data. Some statements about the future values must be made, which could involve lots of uncertainties and inaccuracies that could affect the reliability of your machine learning significantly.
Adaptive vs. ‘locked in’ machine learning – what’s the best?
Can we still create reliable and trustworthy machine learning models? The answer is a cautious “yes.” A way to realize this could be to include some post-processing steps to make the model self-aware of its own uncertainty and risk. An important factor to consider is whether to let the machine learning be adaptive, automatically update, and change to adapt to new environments and data autonomously; or ‘lock in’, to seal the machine learning and do the updating periodically at a predefined frequency.
How to monitor machine learning
An example of a solution is adding change detection and monitoring systems to assess the model validity independently without influencing the normal data flow and the model predictions. Like an anomaly detection system within AIOps, a similar approach can be established for the continuous monitoring of the validity of machine learning models. A trigger or an alert can be created to warn when the machine learning model doesn’t predict well and has a deteriorated accuracy. The model can be updated or replaced by retraining the machine learning model based on the trigger. However, the prediction power and performance of the model may decay until a change is detected. It’s slow in reacting to changed behavior of the incoming data. There’s too much control on the model.
A dynamic approach to monitoring your machine learning
Another approach is tracking the changes by continually updating the model. It can be done, for example, by frequently retraining the model on the most recently observed data. For instance, a group of classifiers (algorithms that characterize what the data is and belongs to) can be maintained and trained on the recent sample dataset. The old classifier can be replaced with the newly trained classifier each time. There is a continuous cycle of monitoring model validity and retraining the model to keep it agile. This way, machine learning can be adaptive to new circumstances and keep its accuracy and trustiness and it will be adaptive and not locked in. The updating is autonomously and automatically done on the changing environment and the underlying behavior of the data.
In summary
The main conclusion to draw is that, with machine learning models and AI systems, we’re able to make sense of complex patterns in large datasets most of the time to obtain reliable predictions; however, this does not mean 100% all the time. Black swan events (unexpected, highly impactful events) could happen that your machine learning cannot capture and will eventually break down. Therefore, we must put the machine learning in AIOps approach in the right context. It’s better than humans, but not the holy grail that we can trust blindly all the time. Constant vigilance is required. That can be achieved with validation and monitoring without losing or missing the many advantages and opportunities these powerful models could provide to your business. Furthermore, principles could be developed to address the risks to your business due to deploying machine learning models. These principles could be guidelines for risk management and tailored to your business and the context in which you deploy machine learning models.

Akif Baser
Currently the Lead Data Scientist on AIOps- & ITOM at Einar and Partners in Amsterdam, Akif has in-depth experience with Machine Learning and AI for IT infrastructure. Predictive modelling, metric-time series, ML-based operating models as well as data strategy around AI.
Akif is one of the leading experts in ServiceNow AIOps with focus on the Metric Intelligence part of ITOM. He has authored whitepapers and content around Metric Intelligence, delivered several masterclasses and been active on consulting clients on how to move towards AIOps.
Previous experiences includes working on predictive modelling in the field of Econometrics and Data Science. With a core-background in technology, Akif has been hands-on with Machine Learning algorithms in C++ and Python since the beginning. These days his technological baseline in combination with a business oriented mindset creates a holistic view in ML-related projects.
