
Modern Service Management represents not only a philosophical change (e.g. DevOps is a core tenant of Modern Service Management), but rethinking the overall approach to IT. It isn’t a framework, and there are no intentions to monetize it. Modern Service Management is simply a continually evolving set of patterns and practices, based on Agile and DevOps practices, leveraging existing and emerging private and public cloud environments, that have been collected from organizations – such as Microsoft, partners, and customers – delivering cloud-scale services.
Modern Service Management provides a differentiated approach to the legacy IT patterns and practices that aren’t delivering results and limit value realization from the cloud. We have shared information on Modern Service Management in two previous ITSM.tools articles:
- Why Transition ITSM to Modern Service Management?
- Modernize ITSM: Transform Digitally and Move from Being Costly to Valued
And now that we’ve shared the Modern Service Management background and vision, usually the question that follows is: “That’s all great, love the money slide, how do we get there?”
This article shares our 12-step journey after a little preamble on the opportunity for organizations.
Modern Service Management: Moving to the cloud
Organizations moving workloads to the cloud have several choices when making that move:
- Extend their current processes, procedures, and manual efforts into the cloud, or
- Modernize and change the game. This means leveraging “cloud-born” approaches, controls, tools, capabilities, and services that are simply not available or feasible on-premises. This approach isn’t new – many IT analysts recommend multi-mode IT for handling new workloads in the cloud, that leverage new approaches and capabilities (e.g. platform-as-a-service (PaaS) and software-as-a-service (SaaS)) versus applying legacy patterns and practices to the cloud.
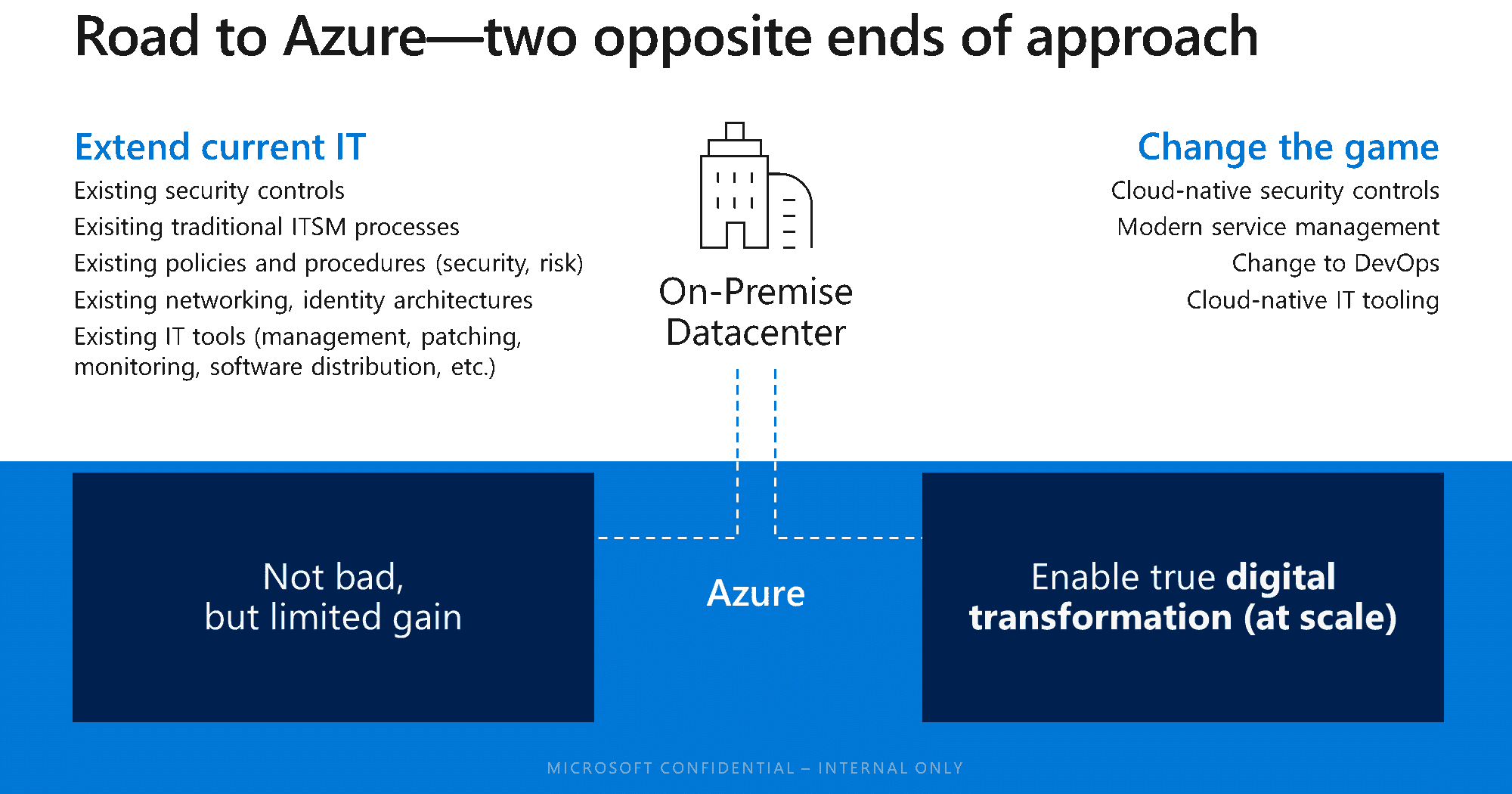
The Evolution of the Modern Service Management journey
What started as a “12-step program” to modernizing IT, would later become a Modern Service Management journey map. We were informed that modernizing IT shouldn’t be based on a “recovery model” so we simply devised the following 12-step journey map instead.
This journey map applies to virtually any cloud workloads such as infrastructure as a service (IaaS), PaaS, and SaaS and would apply to any cloud vendors as well. And, because the cloud concept is available on-premises from solutions like Azure Stack, many of the same principles are already incorporated and can be applied there too.

The Power of DevOps
Some Agile/DevOps approach adoptions have experienced amazing results and amazing success. While others report devastating results and failures that have derailed efforts to change. The reasons for these failures often include:
- Let’s be honest here – politics, turf wars, misalignment, and cultural issues as identified in a recent Harvard Business Review article of the biggest obstacles to innovation in large companies.
- Hitting the accelerator on release without implementing mitigation controls into release (e.g. security and compliance, monitoring, QA, operations, support, etc.)
- Not incorporating the rest of the organization (e.g. AppDev team members are now moving at 100mph, but the rest of the organization is still running at a safe 10mph)
- Lacking executive sponsorship that supports the strategic vision and understands there will be pain at first and that you have to continue to drive through it
- Not addressing the people aspects of change and, in particular, the new roles that will be needed, existing roles that will be changed, and the old roles that should really go away
- Failing to seamlessly integrate IT systems across the DevOps toolchain where release, incident/problem (defect), event, request (enhancements), and feedback loops are easily integrated between AppDev team tools and business operations/support tools.
We believe following this Modern Service Management journey map helps to prevent and/or mitigate the failures and optimizes the successes. The following summarizes the twelve steps and provides useful nuggets of information and takeaways you can apply immediately.
Step 1: Recognize you have a Problem, and a Strategic Opportunity
Often, the IT organization is the last to know or recognize they have a problem. They’re viewed as inflexible (not agile), not cost effective, a black hole of work, slow, or of low quality. They need Modern Service Management.
I don’t believe anyone goes into IT wishing to achieve these attributes. I think the conditions that IT is often put in are the cause of this problem:
- The requirement to deploy, create, and support many applications and infrastructure with no show-back or chargeback mechanism to demonstrate value or compare/compete with outsourcers
- When IT costs are allocated, it’s often arbitrary and not based on unit costs or service consumption
- Little ability to reflect the financial impact of business-imposed decisions, and thus IT is destined to fail as the workload demands far exceeds that which IT can provide (the tragedy of the commons)
What follows is simple:
- The business doesn’t see IT as strategic, relevant, or agile enough to support business
- Worse, IT doesn’t know that the business doesn’t see IT as strategic, relevant, or agile enough to support business

There is a strategic opportunity for IT to become a valued part of any business or institution, a broker of innovation vs. a broker of servers or services, but it must modernize to do this. In other words, IT as a function isn’t going the way of the dinosaurs. But IT needs to evolve and modernize, it needs Modern Service Management.
Step 2: Establish an Adoption and Change Management Cadence
Changing the attitudes and behaviors of the IT organization, as well as employees of the company, is probably the most difficult challenge to modernizing IT. There are so many barriers to change: willingness to change, fear of change and the unknown, fear of losing relevance and impact, job insecurities, or changing dependencies.
Any approach should thus start with the “why”: why modernize, why change, why all the impact?
The reasons are as old as time from a business perspective: increase velocity, increase quality, decrease cost, decrease lead times, improve productivity, and/or increase agility. And it’s important for people to get behind and believe emotionally in these business goals. Even if this means they need to change for the goals to be realized.
Microsoft has partnered with Prosci® for adoption and change management research and guidance. As human beings we all go through change at a different pace. The Prosci® ADKAR®model represents this individual change.
When each step is managed properly, and concurrently across the organization, better change occurs. When steps are skipped or omitted, the change is often less successful:
- (A)wareness – Establish the nature of the change. Explain the need for change and identify the risks of not changing. The objective is: “I understand why…”
- (D)esire – Identify benefits for stakeholders, a personal choice, a decision to engage and participate. The objective is: “I have decided to…”
- (K)nowledge – Understanding how to change, training on new IT and business processes and automation tools, learning new skills. The objective is: “I know how to…”
- (A)bility – Demonstrated capability to implement the change, achievement of the desired change in performance and behavior. The objective is: “I am able to…”
- (R)einforcement – Actions that increase the likelihood that a change will be continued, recognition and rewards that sustain the change. The objective is: “I will continue to…”
This Modern Service Management effort shouldn’t be underestimated. Formalize change and adoption as a minimum for any modernization – technology is becoming easier and more available to everyone outside of IT. It’s going to be a far greater people change than a technology change.
“It ought to be remembered that there is nothing more difficult to take in hand, more perilous to conduct, or more uncertain in its success, than to take the lead in the introduction of a new order of things… Because the innovator has for enemies all those who have done well under the old conditions, and lukewarm defenders in those who may do well under the new. “
Step 3: Identify Initial Services/Apps for the Cloud
While you can transition existing applications to the cloud without modification, often referred to as “lift and shift,” you won’t realize as many benefits continuing to operate them as has been done in the past.
With “lift and fix,” applications are typically modified or extended using cloud computing services and capabilities, while “refactoring” an application often means re-engineering most of the application to use cloud managed services. Sometimes applications can be provided through PaaS or SaaS solutions and don’t have to be developed at all (they can be “configured”).
As first starters, we often suggest net-new applications that can take advantage of cloud synergies not available on-premises. Many new organizations have had the benefit of being “cloud-born” from the get-go. They don’t have to build a data center and/or purchase hardware and can focus more resources on their business objectives.
Existing organizations do not have that luxury. Therefore, selecting new applications that take advantage of cloud native services will be quicker to architect, develop, deploy, operate, and – most importantly – use. The goal of most cloud services is to reduce manual effort in development, support, and/or operations.
Selecting the application is only the first part. A service map, or application dependency map, should exist or be created for the application so that integrations, data sources and destinations, customers, users, and infrastructure dependencies are known. This helps to select the appropriate cloud services and approaches when they are applicable to Modern Service Management.
Step 4: Modernize development/operations and ITSM tools
Modern Service Management represents a consolidation of tooling and the end of siloed islands of information within the IT organization. While traditional ITSM tools have release management and sometimes project management, most of the time these are not the tools AppDev teams use. For Agile or Scrum approaches to application development, app teams leverage tools like Microsoft Visual Studio Team Services, Jenkins, and Bitbucket for release management.
Why? Because they don’t just want to manually track releases as defined in ITIL. They want automated continuous integration/continuous deployment (CI/CD), they want automated testing, they want support for automation and infrastructure as code, and they want to leverage source code control, and most traditional ITSM tools simply do not support this capability.
These release management tools tend not to work well for ITSM workloads either. They aren’t designed to support or be verified for ITIL (nor do they need to be). So there always tends to be a gap, and islands of information, between AppDev teams and operations/support teams.
A Modern Service Management approach assumes that these tools have different purposes and audiences but are easily and seamlessly integrated. This means:
- The release tool drives release schedule and updates
- Both solutions are enhanced and improved easily and independently (they are loosely coupled)
- Traditional change management, which has often been mis-implemented anyway, should become more of a notification engine and strategic approval function. Once established DevOps and Platform teams should have autonomy to release an application without having to go through tons of approvals (assuming controls are in place to mitigate risks)
- Enhancement requests from the ITSM solution go into the release tool backlog and this is synchronized bi-directionally
- Incidents should be minimized with a DevOps approach, but they’ll still happen and need to channel from operations/support teams to the defect backlog in the release tool. Same with problems
- Defects accepted in testing should be synchronized bi-directionally between release tools and ITSM tools that support problem management
There are other service management/DevOps handshake scenarios that will build incredible bridges and value within an IT organization and help jumpstart a move to the “Intelligent Cloud Organization®”
Step 5: Plan and enable automated service provisioning
Automation is often an after-thought, or “subsequent phase,” when IT organizations seek modernization. But automation should be core to modernization. All cloud services are built on automation. A cloud service provider cannot be profitable with manual, human driven effort.
Automation therefore should be a key core strategy, and there is nothing wrong with multiple automation engines. But a framework should be established for which workloads make sense for which automation platform. Manually provisioning resources in the cloud destroys the value proposition the same way it has with private cloud and virtualization.
I believe that private cloud often failed to achieve its original objective – not technically, but from an implementation perspective, because organizations didn’t embrace the concept of private cloud, primarily just achieving virtualization with a manually-driven effort overlay.
Step 6: Evolve development and deployment patterns
As Modern Service Management is based on Agile and DevOps, this requires a change in development, deployment, and operations practices. Regardless of whether you’re an AppDev shop or deploy commercial software packages, there are Agile/DevOps-based approaches to releasing applications.
In fact, many vendors, including Microsoft, have moved their applications and services to release pipelines. Why? Steve Murawski, Cloud and Datacenter Management MVP Principal Engineer for Chef Software, wrote the following forward for Microsoft “Release Pipeline Model” whitepaper:
“It is time to stop lying to ourselves. What we’ve been doing is not working. Our infrastructure is a mess. Our application deployments are a nightmare.
We spend our nights and weekends fighting fires of our own making. We put more effort into shifting blame than improving our environments.
Documentation lags because of last minute changes or ever-shifting deployment targets. Convoluted change management leaves critical, important tasks waiting for urgent, less important work. We need to find a better way, but we are not alone.
Over the past few years, research has been ongoing into the state of IT and the impact of these wacky “DevOps” ideas. Well, the data is in and it doesn’t look good for traditional IT processes.
Per the “State of DevOps Report” and the “DevOps and the Bottom Line” studies and data analysis performed by Dr. Nicole Fosgren, IT performance is a key factor in an organization’s profitability, productivity, and market share. IT can be a competitive advantage, but it requires a mind shift and process shift from the traditional way of doing things.
And the businesses are noticing. They are finding cheaper and faster ways to access the services we once held the sole dominion over. Once the shackles of traditional IT management have been shed, business is being unleashed to try new things at a faster pace than before and at less cost.”
What does this mean? Organizations that are still encumbered to legacy, ITSM-heavy release and change management processes are falling behind. They’re failing their businesses.
We often use the following analogy of a traffic light as an analogy to this new model of continuous flow:
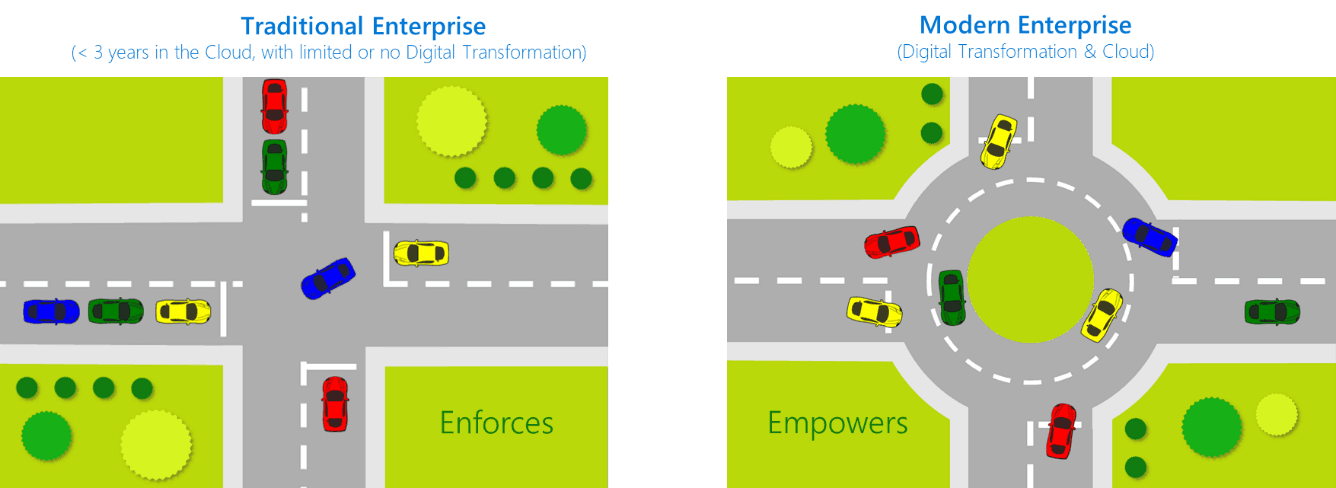
I know in many parts of the United States, and probably elsewhere, former intersections with traffic lights are being replaced with roundabouts or turning circles. The reason why is simple:
- Optimized traffic flow (you don’t have to stop at all if there is no traffic)
- Low-technology, autonomous control – you as a driver make the decision when to enter the circle based on pre-established, “directive” controls (e.g. drivers entering the circle must yield to those in the circle already)
- Much fewer accidents and the severity of accidents is reduced. Roundabouts reduced injury crashes by 75% at intersections where stop signs or signals were previously used for traffic control, according to a study by the Insurance Institute for Highway Safety (IIHS)
If we apply this analogy to releasing software, applications, services, and updates:
- Smaller updates more often that are continuously deployed
- The release pipeline introduces release rings so that issues with first adopters do not impact the business and adjustments can be made to the broader community
- Deployment teams have autonomy to roll-forward/roll-back based on automated testing, user experience, and error logs. Testing takes place in production
- Less “crashes” and failures
- Increased agility and speed.
Step 7: Identify/select monitoring and automation hooks in applications
Again, another “failure mode” of improperly approaching DevOps is not incorporating controls into releases. These can be preventative, detective, or directive. Those of us who endured Sarbanes-Oxley projects over the last two decades understand preventative and detective controls:
- Preventative controls prevent an activity, process, or system from getting out of compliance
- Detective controls detect and report when an activity, process, or system is out of compliance
- Directive controls are policies that drive appropriate behavior but are not necessarily enforced
As virtually all services and applications in the cloud have telemetry and are monitored, applications built or deployed by organizations should incorporate health telemetry, as well as having monitoring and automation built in. This is poorly lacking from many legacy on-premises solutions today.
Automation teams and monitoring teams (or Platform teams) should provide the monitoring and automation service, but both the monitoring of logic and workflow should be defined and implemented by the DevOps and Feature teams. This allows monitoring and automation to be incorporated as part of the release pipeline and Modern Service Management.
How you monitor is as important as what you monitor. Quality should be first and foremost. Quality as defined by the customer. Processing a transaction, posting to a ledger, and even sending an email are all testable.
They’ll be tested when the application is being developed or implemented (COTS), so why not incorporate test scripts into monitoring?
Step 8: Identify, train, and prepare
We ask customers: “If you take security and service management misperceptions, perceptions, and realities off the table, what is left that keeps you from moving to the cloud?” There really isn’t much left other than readiness. The premise of DevOps is that teams are formed across technologies and across the organization with a greater focus on skills and less on specific roles. Everyone cannot attend one-week off-site training courses, but there are so many options today that mitigate this need.
Most DevOps topics are available for free or minimal charge to learn. This includes coding and development, automation, release management, sprints, Epics/themes/user stories, etc. You don’t have to be “certified” in DevOps to undertake DevOps, but experience and a willingness to experiment and make mistakes is necessary.
Simply incorporating the customer and operations and infrastructure with application and development teams doesn’t require consulting or training. Aligning releases around a release pipeline doesn’t require biblical changes to your organization. Most automation platforms also have information and instruction available online. Start to identify what can be automated and automate it.
Step 8 of the Modern Service Management journey addresses the knowledge component of change in the Prosci® ADKAR®model mentioned previously.
Step 9: Identify current process modifications and gaps
By now it should be obvious what needs to change from an existing process perspective. Processes must evolve in order to modernize IT. Existing legacy-based ITSM processes have to change. Some claim “But we’re ITIL compliant” but I’m not sure what that means.
But more often than not processes have been mis-implemented anyway. Case in point: the need for every change to go through change management is NOT in the ITIL books. Several examples of gaps in processes that need to change are:
- Service desk. It should evolve from the “ticketing” fetch and forward concept. For starters, interactions should start via a self-service portal, or better yet, with artificially intelligent chatbots that are integrated into applications where possible. Service desk/support teams evolve to more of a readiness and stewardship role and can perform diagnosis to help people help themselves.
- Change management. With team autonomy, iterative change is established as part of a release pipeline to inform/notify change management, so support teams are aware of when and what changes are implemented. Support teams are part of the platform and DevOps teams, so changes should be expected with no surprise.
- Release management. Align releases to the release solution of the AppDev team. It becomes the notification component and tracks from the AppDev team release solution. If rotating teams associated to releases participate in support (the software factory concept), support team membership updates should automatically include resources from the AppDev team supporting a specific N or N+1 release in the modern ITSM solution.
- Incident management. This should be monitoring-focused with Modern Service Management. Anytime an incident (a failure) comes from an employee of the company, it should be backlogged as a failure. True failure should be detected by monitoring and if your customers are reporting your failures, you wasted your money on monitoring solutions.
Leveraging DevOps and Agile, married to infused control objectives has shown huge improvements in the reduction of failures before and after releases to production (check the State of DevOps report – any year) - Problem management. Here there should be multiple integrations between defect backlog and the known error database which should be automated.
Microsoft Visual Studio Team Services and Dynamics 365 Customer Experience platform deliver against this. For more information please see:
- DevOps in the Enterprise
- Azure solutions for DevOps
- Visual Studio Team Services
- Modern Service Management in the Intelligent Cloud
Other application release solutions and ITSM solutions will have similar capabilities as well.
Step 10: Provide role transition support
Like major Enterprise Resource Planning (ERP) system transitions of the past, those involved in making the future happen still have work that needs to be performed using the legacy solution. To address this, plans should be put in place to provide fill-in staffing, remediating the work to an outsourcer, or eliminating the work altogether.
The point here is that when transitioning to modern, new workloads this should be done by those who will own and drive it in the future. If an organization brings in an outsourcer for the new, and relegates legacy to its employees, that means the organization is investing in switching to an outsourced IT model as more workloads transition to new model. A good use of outsourcing is having the outsourcer maintain the legacy while the IT organization transforms to the new through Modern Service Management.
Step 11: Implement changes to processes
As defined in step 9, where changes to processes are identified, those changes need to be implemented. Step 10 provides resource support to make this happen. This is where executive sponsorship is the most important.
Like many steps in the 12-step journey, iteration may be the key to success. Drastic changes to process may not be possible in a single iteration, but if we apply the same agile, iterative approach to process changes, with each sprint comes new flexibility and new capability.
Step 12: Transition workloads to operate as a service
This step is the simplest of all. If you’ve done all or part of the prior 11 steps, step 12 is simply the transition of minimally viable products (MVPs) into production. As shared before, this may be for specific new applications in the cloud to learn how to manage and operate.
Or, for large migrations, it may be a lot of iterative legacy operations due to lift and shift transition. The key to step 12 is to continuously and iteratively improve towards all of the Modern Service Management imperatives that have been shared before.
In closing…
In the past, required business and IT organizational changes were big and obvious. Today these changes creep up unnoticed and, for instance, if you’re just now starting to work on a digital transformation strategy, then you’re probably already in catch-up mode.
Chances are there is another business, organization, even in government entity, vying to displace you as a competitor, as a service provider, as a product, solution, or service. Doing nothing is devastating. Incremental changes maintain the status quo. Doing incremental improvements such as those outlined above will not be sufficient going forward over time.
The greatest value is in leveraging the steps above to support digitally transforming the business, or organization, and this starts with modernizing and transforming IT itself to support that change. Businesses, governments, and other organizations will do, and are doing it today with or without IT involvement. Fate rarely calls us at a moment of our choosing. Now is the time to choose to think big… think Modern Service Management.
Further Reading
Would you like to read an article on service availability and availability management in ITSM?
Please use the website search capability to find other helpful ITSM articles on topics such as cloud platforms, managed cloud services, cloud deployments, cloud-based services, optimizing processing power, data storage, hardware and software, physical servers, public cloud services, load balancing, handling sensitive data, load balancing needs, SaaS application management, cloud storage, application and data management, cloud resources, Amazon Web Services (AWS), cloud solutions, on-premise infrastructures, running applications in the cloud, and how to reduce costs in the long term.

John Clark
John Clark is a Cross-Domain Solution Architect (CDSA) in Microsoft Enterprise Services as well as the Worldwide Modern Service Management Community Lead and former Subject Matter Expert.
John was formerly an ITSM Solution Architect for Microsoft Enterprise Services as well and continues to incorporate modern ITSM in his new role. As a Microsoft CDSA, John is responsible for shaping opportunities with customers leveraging and implementing cross-domain Microsoft solutions that incorporate Azure, Office 365, Dynamics 365 and Microsoft 365.
John has received several honors in recent years, including being selected for the WW ITSM Communities SME Award, Microsoft Sr. Technology Leadership Program (2014), and the Americas Gold Club (2016). He is also a past president of the Ohio Valley itSMF USA LIG and a former LIG of the Year recipient.

Kathleen Wilson
Kathleen is an Architect at Microsoft for the Cloud and Infrastructure Management Center of Excellence, focusing on developing solutions for management and adoption of private, hybrid, public clouds, and DevOps.
Kathleen’s strengths lie in understanding what is needed to adopt, support and operate solutions either on premise or in the cloud. She has over 21 years of experience in IT and has worked in both IT operations and consulting.
Prior to her Architect role, Kathleen was a consultant for Microsoft Consulting Services Canada who focused on assisting customers with the adoption of Microsoft products, service management, and private cloud. Kathleen leads a worldwide community of peers who have transformed traditional ITSM into modern service management.
Kathleen achieved her ITIL Foundation certification in 1998, and is currently an ITIL v3 Expert and is actively tweets about modern service management to get people to rethink traditional service management fundamentals and make them more modern and actionable with enabling technologies.
Kathleen co-authored a MS Press book, Optimizing Service Manager, and was a contributing author to the System Center 2012 Service Manager Unleashed book. She is an Edutainer and has spoken at many internal and external Microsoft/industry events.
